Implémentation
Avec la rédaction du présent travail, le projet
ETYMO se termine officiellement. Nous constatons, cependant, qu’il
existe encore de nombreux aspects qui pourraient être améliorés
ou rajoutés. Afin de garantir une future amélioration
du programme, nous avons décidé de le rendre publique
de façon à ce que ceux ou celles qui le souhaitent
puissent le modifier selon leurs propres désirs et besoins.
Toutes les sources nécessaires ont donc été
incluses dans le CD-ROM qui accompagne ce travail. Le but des
chapitres suivants consiste à les présenter brièvement.
Comme nous l’avons dit maintes fois, il existe deux versions
du programme dont l’une marche sous MS-DOS et l’autre sous
UNIX. Il est important de souligner que, du point de vue technique,
ces deux versions n’ont rien en commun.
C’est aussi la raison pour laquelle nous les présenterons
séparément.
Version MS-DOS
Cette version, implémentée directement sous MS-DOS
et traduite avec le compilateur C++ de la GNU Free Software
Foundation (plus précisément la distribution DJGPP mise
à disposition par Delorie Software)
se compose des fichiers suivants :
|
ETYMO.CC
|
programme principal
|
|
DTYPE.H
|
définitions des types de données
|
|
PARSER.H
HANDMADE.H
READFUNC.H
|
parser
|
|
CALC.H
|
fonctions pour le calcul
|
|
TREE.H
|
traitements des arbres
|
|
STAT.H
|
fonctions statistiques
|
|
VIRTUAL.H
|
écran virtuel
|
Les fichiers PARSER.H et READFUNC.H ont été créés
à l’aide du programme PARSGEN.CC et du fichier
PARSDEF.PAR qui ont également été inclus sur
disquette.
Le parser
Le parser a été créé à l’aide
du programme PARSGEN.CC. Ce programme utilise un fichier de
définitions (PARSDEF.PAR) qu’il traduit en deux fichiers
C, à savoir PARSER.H et READFUNC.H. Le fichier PARSDEF.PAR
contient deux types de définitions : (1) les groupes de
caractères et (2) les fonctions :
| (1) G = "c1c2 .. cn" ; | G = nom du groupe
c1 .. cn = caractŤres
|
| (2) f0 => g1 : f1 | g2 : f2 | .. | gn : fn ; |
|
Ces deux définitions sont ensuite traduites dans des
fonctions C du type :
|
(1) #define G "c1c2 .. cn" PARSER.H
int is_G( char c ) {
if (strchr( G, c ) != NULL) return 1;
else return 0;
}
(2) int f0( char* s, int i ) { PARSER.H
if (read) read_f0( s, i );
if (is_g1(s[i+1])) return f1( s, i+1 );
else if (is_g2(s[i+1])) return f2( s, i+1 );
: : :
else if (is_gn(s[i+1])) return fn( s, i+1 );
else return i+2;
}
void read_f0( char* s, int i ) { READFUNC.H
/* insťrez ici vos propres commandes */
return;
}
|
La variable read peut être utilisée pour
passer du mode « tester » (read=0) au
mode « lire » (read=1). Les opérations
à effectuer dans le mode « lire »
peuvent être insérées dans la fonctions
read_f0().
Certaines fonctions qui n’ont pas pu être générées
par PARSGEN.CC ont été écrites à la main.
Elles se trouvent dans le fichier HANDMADE.H.
Structures des données
Lorsque le parser lit le catalogue de règles, il sauvegarde
les informations dans différentes variables. Suivant le type
d’information – traits, littéraux, symboles ou
règles – il choisit d’autres structures :
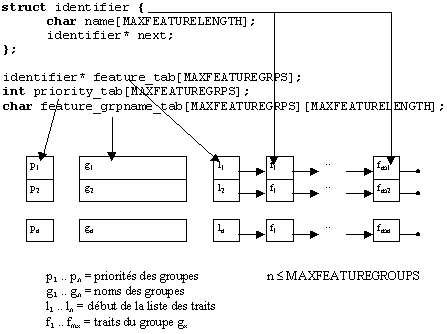
traits
struct identifier {
char name[MAXFEATURELENGTH];
identifier* next;
};
identifier* feature_tab[MAXFEATUREGRPS];
int priority_tab[MAXFEATUREGRPS];
char feature_grpname_tab[MAXFEATUREGRPS][MAXFEATURELENGTH];
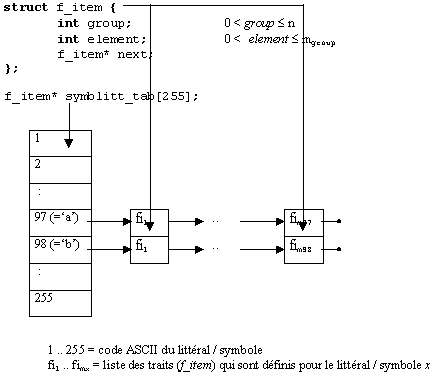
littéraux et symboles
struct f_item {
int group; 0 < group £ n
int element; 0 < element £ mgroup
f_item* next;
};
f_item* symblitt_tab[255];
règles
struct r_item {
char c; caractŤre de base (symbole, littťral, joker)
char m; marqueur
int wx; position de la premiŤre occurrence de la condition 1
int ns; nombre des phonŤmes concernťs 2
f_item* list; dťbut de la liste des traits dťfinis pour c 3
r_item* assign; r_item auquel ce r_item a ťtť assignť 4
};
struct rule {
int t; temps
r_item* a[MAXCONDLENGTH]; condition
r_item* b[MAXCONSEQUENCES][MAXCONSLENGTH]; consťquences
char* comm; commentaire
};
Quant aux mots qui sont scannés avec le même parser
ils sont sauvegardés dans la structure suivante :
struct word {
int t; temps
(short int)* s[MAXWORDLEN]; pointeurs sur les phonŤmes
int lastrule; derniŤre rŤgle utilisťe
int rule_used; rŤgle utilisťe pour ce mot
int done; ťvolution terminťe
int posx, posy; coordonnťes x et y
int subelem; nombre de successeurs
word* up; prťdťcesseur immťdiat
word* down; successeur immťdiat
word* right; ťvolution parallŤle ŗ droite
word* left; ťvolution parallŤle ŗ gauche
};
Lors de la création d’un arbre évolutif, la
variable head pointe sur le début de celui-ci :

Les variables lastrule, rule_used et done
sont seulement utilisées pendant le calcul. Les variables
posx, posy, up, left servent à la
représentation visuelle. Quant aux phonèmes s[0]
.. [MAXWORDLEN], il s’agit de pointeurs sur des vecteurs
de traits.
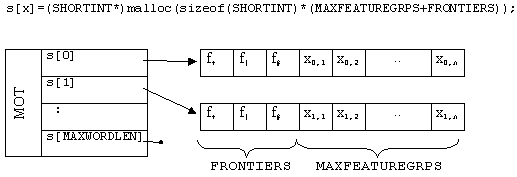
f+,
f|
et f#
sont réservés aux frontières et peuvent contenir
soit 0 (=pas de frontière) soit 1 (=frontière).
x0,0
.. xMAXWORDLEN,n
contiennent des traits définis par l’utilisateur : la
valeur de xp,g
désigne le trait du groupe g dans le phonème p.
Version UNIX
Comme son nom l’indique, cette version a été
implémentée avec le système d’exploitation
UNIX. Le compilateur gcc a été utilisé
pour sa traduction. Le programme se compose des fichiers suivants :
|
FICHIER
|
DESCRIPTION
|
|
Etymo.c
|
programme principal
|
|
EtyRules.l
|
fichier lex pour le parsing des règles
|
|
EtyRules.y
|
fichier yacc pour le parsing des règles.
|
|
EtyRules.c / EtyRules.h
|
|
|
EtyWords.l
|
fichier lex pour le parsing des mots
|
|
EtyWords.y
|
fichier yacc pour le parsing des mots
|
|
EtyWords.c / EtyWords.h
|
|
|
EtyParser.c / EtyParser.h
|
fonctions supplémentaires du parseur
|
|
EtySymbols.c / EtySymbols.h
|
traitement des symboles (parseur)
|
|
EtySolve.c / EtySolve.h
|
calcul
|
|
EtyGlobals.c / EtyGlobals.h
|
erreurs / avertissements
|
|
EtyTools.c / EtyTools.h
|
fonctions principales
|
Les différents pas nécessaires à la
compilation du programme ont été automatisés
dans les deux scripts DOALL et RENAMEYY.PL.
Le parseur
La version UNIX utilise un parseur qui a été généré
à l’aide des programmes lex et yacc.
Ces deux outils utilisent des définitions pour produire des
parseurs lexicaux (lex) et syntaxiques (yacc). Étant
donné qu’il existe de nombreux ouvrages qui expliquent le
fonctionnement de ces deux programmes,
nous n’entrons pas ici dans les détails.
Quant aux fichiers qui contiennent les définitions des deux
parsers utilisés par ETYMO, ils s’agit des suivants :
|
EtyRules.l
EtyRules.y
|

|
parseur des règles
|
|
EtyWords.l
EtyWords.y
|
|
parseur des mots
|
À noter donc que la version UNIX utilise deux parseurs
différents pour les règles et les mots.
Structures des données
La tâche du parser consiste à analyser le catalogue
de règles et à traduire les informations qu’il
contient dans des structures internes. Ces structures sont de
différents types, selon que les informations à
sauvegarder sont des traits, des littéraux, des symboles ou
des règles :
traits
Le parser commence
par dresser une liste de « symboles »
: un « symbole » est un « nom »
ou, pour utiliser le terme technique, un « identifieur »
(identifier), c’est-à-dire une séquence de
caractères qui « identifie » un trait ou
un groupe. Chaque symbole reçoit ensuite un numéro
univoque appelé « index » :
typedef char Identifier[128];
typedef struct symrec * SymbolList;
typedef struct symtabrec * SymbolTable;
typedef struct symrec { correspond ŗ un symbole
SymbolList next; symbole suivant
int nr; index du symbole
Identifier id; ę identifieur Ľ du symbole
} SymbolRec;
typedef struct symtabrec { correspond ŗ une liste de symboles
SymbolList root; premier ťlťment dans la liste
SymbolList sentinel; dernier ťlťment dans la liste
int NextNr; prochain index libre5
} SymbolTableRec;
La structure se présente donc comme suit :

Il existe à
l’intérieur du programme deux variables globales du type
SymbolTable, à
savoir EtyAttrSymbols qui
sauvegarde les noms des traits et EtyGroupSymbols
qui contient les noms des groupes.
Quant aux index
(nr), ils peuvent ensuite
être réunis dans des chaînes (queues) :
typedef struct idxrec * IndexList;
typedef struct idxquerec * Queue;
typedef struct idxrec {
IndexList next; ťlťment suivant dans la chaÓne
int index; index de l?ťlťment (=> identifieur)
} IndexRec;
typedef struct idxquerec {
IndexList root, sentinel; premier et dernier ťlťment de la chaÓne
int size; nombre des ťlťments6
} QueueRec;
Ces chaînes peuvent, à leur tour, être utilisées
pour définir les traits :
typedef struct attrrec * Attr;
typedef struct attrrec {
Attr next; trait suivant
int name; nom du trait
int index; index du trait
Queue dominators; chaÓne des traits dominants
int group; index du groupe
} AttrRec;
et les groupes :
typedef struct grprec * Group;
typedef struct grprec {
Group next; groupe suivant
int name; nom du groupe (=> identifieur)
int index; index du groupe
Queue dominators; traits dominants
Queue attributes; traits du groupe
} GroupRec;
Schématiquement, le parsing d’une définition de
traits se présente donc de la façon suivante :

Finalement, les traits et les groupes ainsi définis sont
sauvegardés dans les deux variables globales
Group EtyGroups[MAXGROUPS];
Attr EtyAttrs[MAXATTR];
littéraux et symboles
Il n’existe
qu’une seule structure qui est valable pour les deux types
d’information
:
typedef Queue AttrQueueVector[MAXGROUPS];
typedef int AttrVector[MAXGROUPS];
typedef struct varrec {
AttrQueueVector attrqV; traits par groupes
Queue attributes; traits en chaÓne
AttrVector typeV; type pour chaque groupe7
AttrVector attrV; traits par groupes dans un vecteur
} Variable;
Les littéraux et les symboles sont sauvegardés dans le
vecteur global
Variable EtyVariables[MAXVARIABLES]; MAXVARIABLES = 256
La structure est
donc assez similaire à celle présentée dans (p.
) :

Le code ASCII du caractère (littéral ou symbole)
correspond à l’offset dans le vecteur.
règles
typedef struct rulerec * Rule;
typedef struct rulerec {
Rule next; rŤgle suivante
int id; numťro de la rŤgle
int epoch; temps
Cons condition; condition
Cons consequence; consťquence
Cons lcontext; contexte gauche
Cons rcontext; contexte droite
char * description; commentaire
} RuleRec;
De nouveau, il
existe deux variables qui pointent sur le début et la fin de
la liste des règles :
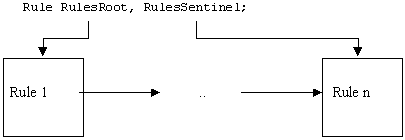
La partie principale des règles se trouve dans la structure
Cons :
typedef enum { INIT, TERMINAL, SEQUENCE , CHOICE } Category;
typedef enum { SYMBOL, LITERAL, JUMP, JUMPB } TerminalType;
typedef struct consrec * Cons;
typedef struct consrec {
Cons first; ťlťment immťdiat
Cons rest; ťlťment(s) suivant(s)
Cons prev; ťlťment prťcťdent
Category cat; catťgorie (INIT, TERMINAL, SEQUENCE, CHOICE)
TerminalType ttype; type du caractŤre (SYMBOL, LITERAL, JUMP, JUMPB)
char name; caractŤre de base
int marker; marqueur
Queue moreAttributes; traits supplťmentaires
Queue moreBounds; frontiŤres
AttrVector typeV; ??
AttrQueueVector attrqV; ??
Cons word_first; premier ťlťment dans le mot
Cons word_rest; dernier ťlťment dans le mot
} ConsRec;
La structure Cons est multifonctionnelle dans le sens où
l’élément cat peut prendre différentes
valeurs qui déterminent son emploi. Afin de pouvoir mieux
illustrer le fonctionnement de cet élément, voici un
schéma de la structure générée pour le
contexte a { b, c } d :
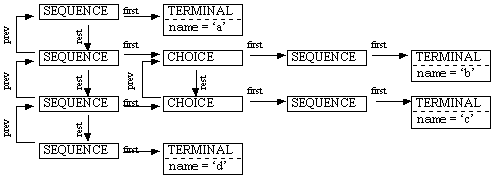
Les éléments SEQUENCE représentent donc un
rapport conjonctif, tandis que les éléments CHOICE
correspondent à un rapport disjonctif.
Etant donné que seul le contexte peut contenir des éléments
disjonctifs, la catégorie CHOICE n’est pas utilisée
pour la condition et la conséquence.
Quant aux mots, ils sont également sauvegardés dans des
structures du type Cons, et, dans ce cas aussi, la catégorie
CHOICE n’est pas utilisée.
Stack
Pour la vérification de la condition et du contexte, la
version UNIX utilise une pile (stack) : dans celle-ci, le
programme marque par 0 les bifurcations qui n’ont pas
encore été complètement traitées. Si, par
contre, toutes les alternatives ont été essayées,
la bifurcation est marquée par 1. Si nous reprenons
l’exemple du contexte a { b,
c } d, cela donne :
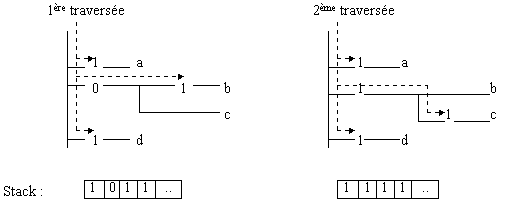
La pile est sauvegardé dans la variable altstack[].